Why this paper
Many ML articles exist but few talk about how the sausage gets made. They are often based on toy or clean benchmark datasets, which are quite different from what we get in real world. That’s why I enjoy reading survey papers. They interview people in the field like us and try to address common pain points to find a broader picture.
For the past several years, I have been noticing a trend in ML community. Many practitioners tend to ignore data quality but instead put all their efforts into models and algorithms. I find it very troubling because many problems in real-world ML are caused by data-related issues. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI talks about this pattern based on the interviews from dozens of ML practitioners all over the globe.
Data cascades
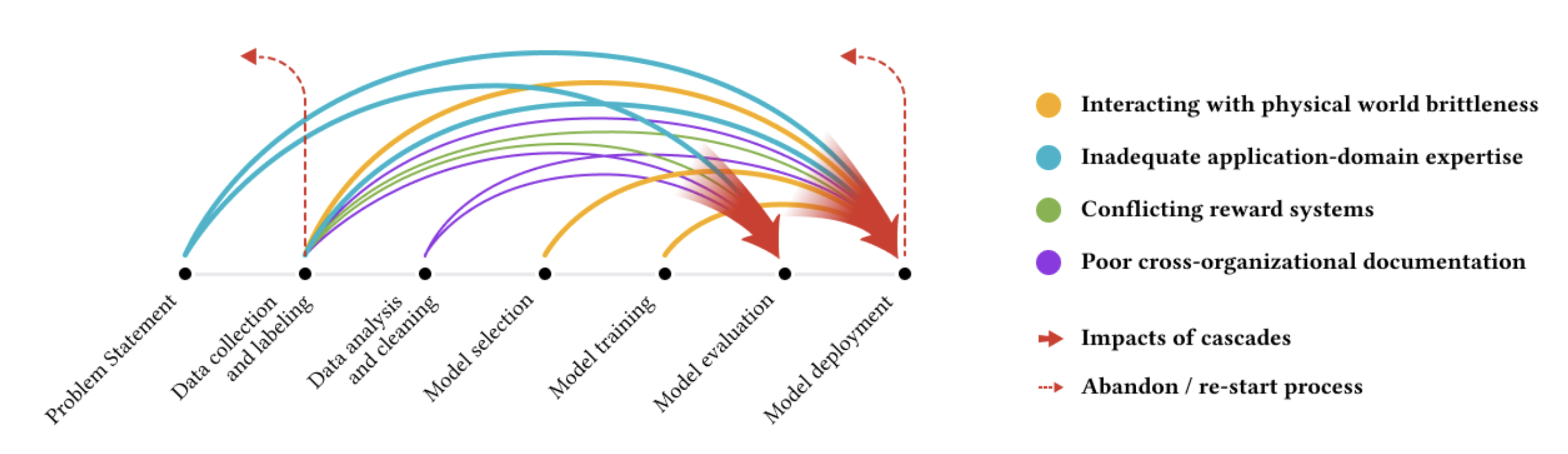
The paper focuses on “data cascades,” a series of compounding negative events due to data-related issues. The authors say the problems are wildly prevalent (92% reported experience at least one type of data cascades). During the discussion, we thought about sampling bias because those who are ignorant of these problems may not be able to recognize them. Indeed, they are often opaque because there are no clear indicators and often discovered later. Data cascades often lead to technical debt and harm to beneficiary communities. They can sour relationships between stakeholders and in extremely cases, force ML practitioners discard entire datasets. Figure 1 shows the schematic of the data cascades. We thought the figure wasn’t particularly informative because too many arrows exist between the points. We hoped that the authors explained why there aren’t arrows between certain points.
High-stake domains
Data cascades are more critical in high stake domains such as landslide detection, suicide prevention, and cancer detection. There are several reasons:
- More ML applications are deployed in these domains where more direct humanitarian impact exists.
- This impact can be disproportionate towards vulnerable communities.
- It is often very challenging to acquire high quality data in these domains.
- The problems frequently require more multidisciplinary approach.

The authors find that the problems are due to human factors. Unfortunately solutions have been focusing on other issues such as database, legal, or license. To gather firsthand experience in the field, the authors interviewed 50+ ML practitioners all over the world, ranging from the US to India and African countries, and from founders to developers. Table 1 summarizes various high-stake domains. It was fascinating for us to learn that ML is used in areas as landslide detection, poaching prevention, or regenerative farming. It would have been more interesting to see how data cascades create specific negative consequences in some domains.
Data cascade triggers
The authors introduce three triggers that cause data cascades.
Physical world brittleness
Physical world changes over time and thus often ML systems can’t produce robust results. Data drifts due to hardware (measurements) and environmental changes are commonly mentioned in ML Ops literature. In high-stake domains, they become more pronounced because training data are very limited and policy or regulation changes can impact the ML systems in various ways.
Inadequate application-domain expertise
Most ML practitioners are not equipped with domain knowledge. All of us admitted that our academic background does not match to the domain that we work in. Even though close collaboration between domain experts and ML practitioners is always emphasized, in practice the authors find that domain experts are often detached from the larger impact of the applications. The authors explain two specific types of problems:
Subjectivity in ground truth: Areas such as insurance claim approval or medical imaging for cancer detection involve highly specialized and often subjective decision-making. To build a reliable and robust ML system, it is necessary to standardize the decision-making criteria and find consensus. However, ML practitioners are asked to rush through the development process, and thus do not have time to address it.
Poor domain expertise in finding representative data: ML practitioners often start building ML applications without involving domain experts much because the practitioners simply believe that data are reliable. However, because they lack domain knowledge, practitioners make incomplete assumptions, which results in disparity between data collection and deployment. This often leads to poor and unreliable model performance.
Conflicting reward system
Data collection and any data-related work are often considered non-technical and undervalued. The situation gets worse for frontline workers because they are asked to collect and curate field data on top of their existing responsibilities but they are not well compensated.
Poor cross-organizational documentation
Metadata about data collection, quality, and curation are also often missing. Some good practices the authors suggest involve keeping good documentation on reproducible assets such as data collection plan, data strategy handbooks, design documents, file conventions, field notes, and so on.
Broader context
Data cascades discussion can be extended to bigger problems in ML community.
Incentives and currency in AI
Because of the low incentives, data-related work are not rewarded or even tracked. This makes us difficult to get buy-in from stakeholders. The situation is similar in academia as well. Most practitioners and researchers focus on developing algorithms but they rarely mention or work on data. The title “Everyone wants to do the model work, not the data work” was a verbatim from an interviewee. Unfortunately, we were all able to relate to this quote.
Data education
Most ML or data science curricula lack any mention of data quality or ethics. They use toy datasets or very clean benchmark datasets. As experience ML practitioners, we wholeheartedly agreed with this finding. We lamented that these courses do not prepare students with practical knowledge because one never works with clean datasets in real world. Some of us have experienced this pattern firsthand because we have been interviewing candidates for an ML practitioner position and found that the candidates who only worked with clean datasets (or primarily worked on algorithms) often lack basic practical ML knowledge.
Data bootstrapping
Data bootstrapping describes ML practitioners’ use of other data sources such as established data services or existing datasets to create their own dataset. For most of us, it was surprising to learn that many ML practitioners in high-stake domains in countries from Global South had to collect data from scratch. We agreed that challenges in data collection and lack of access to quality data would create inequality between countries.
How to address data cascades
The authors introduce several ways of addressing the problem of data cascades. They introduce the concept of “data excellence”, an effort to “focus on the practices, politics, and values of humans of the data pipeline to improve the quality and sanctity of data, through the use of processes, standards, infrastructure and incentives”.
From goodness-of-fit to goodness-of-data
The first is to use the right metric to evaluate data quality. Many ML practitioners use model performance metrics such as accuracy and RMSE to evaluate data quality. Some of us had a similar experience. We had to argue that model metrics shouldn’t be used to make a decision on data-pipeline and data-quality features. We hope that the authors can introduce specific examples of goodness-of-data metrics in the future.
Incentives for data excellence
There are several ways to address the low incentives of data work. First, journals and conferences should require dataset documentation, provenance, and ethics as mandatory disclosure. Second, organizations should reward data-related work similar to how good software engineering is rewarded. Finally, partnership between stakeholders can nurture data excellence by sharing the reward on data-related work such as data collection, anomaly identification, and model verification.
Education and visibility
The authors argue for real-world data literacy in AI education, which includes training on data collection, infrastructure building, data documentation, data sense-making, and data ethics and responsible AI in general. Increasing the data visibility in ML lifecycle is important as well; implementing good monitoring system is one of the most important ML Ops practices anyway.
Final thoughts
Some of us found this paper vindicating because we have been advocating for data quality at work and had to fight for the attention it deserves. The paper helped us share our own practices at work that address data-related issues especially data collection, curation, and post-deployment data problems. Even though we generally agreed with authors’ suggestions, some of us wanted something more specific, like a case study. Overall, we found the paper interesting and insightful. We thought it would be beneficial to read the paper with our colleagues at work to start a discussion for data excellence.
If you found this post useful, you can cite it as:
@article{
austinmljc-2022-data-cascades,
author = {Hongsup Shin},
title = {Everyone wants to do the model work, not the data work: Data Cascades in High-Stakes AI},
year = {2022},
month = {10},
day = {27},
howpublished = {rl{https://austinmljournalclub.github.io}},
journal = {Austin ML Journal Club},
url = {https://austinmljournalclub.github.io/posts/20221027/},
}