Why this paper?
I’ve been interested in AI safety and responsible AI for several years, and the rise of LLMs has certainly increased stakes. Currently there is an intense arms race among several major tech companies and Anthropic is one of them. They recently published a paper about their LLM and claims to adopt a more cautious approach than others by designing their LLMs to minimize potential harm. They call this constitutional AI (CAI) because their LLMs follow a constitution of principles. I wanted to learn more about how they teach their algorithm to follow these principles.
Background knowledge
To understand this paper properly, it’s better to be familiar with AI alignment problem and reinforcement learning from human feedback (RLHF). AI alignment is about aligning AI systems’ design and values with humanity values such as honesty. Norbert Wiener, an AI researcher back in 1960s, described the AI alignment problem as following:
“If we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively (…) we had better be quite sure that the purpose put into the machine is the purpose which we really desire.”
Regarding RLHF, I recommend this great summary from Hugging Face. At its core, RLHF is an attempt to distill human feedback into a model (often called reward or preference model) when training LLMs. This is because human feedback is often expensive to collect and difficult to generalize. An important thing to know is that to train this model, practitioners often use ranked preference modeling where human annotators are asked to rank generated text ouptuts from language models. The assumption here is that this approach may mimic human preference of certain responses over others. And because of this preference approach, RLHF papers use Elo scores, a rating system originated from chess to show a player’s winning rates, to evaluate model performance.
In terms of the alignment values, Anthropic chose honesty, helpfulness, and harmlessness. The detailed definition of these concepts are described in one of their previous works:
Motivations
The first motivation was scaling supervision. Given that LLMs require numerous examples, it’s better to automate the supervision process and use human annotators to get more curated and high quality answers. This is a similar idea behind the preference modeling in RLHF. The authors called theirs “reinforcement learning from AI Feedback” (RLAIF, not RLHF). A more interesting motivation was building a non-evasive and yet helpful AI assistant. Many currently available AI assistants often simply refuse to answer questions to harmful prompts (e.g., simply saying “I don’t know” or “I can’t answer that”). Their model was never evasive but tried to explain the reasoning behind their negative response to harmful questions. Finally, similar to the first point, they claimed that distilling human supervision into a model could help better understand general aspects of human feedback from many crowd-workers.
The Constitutional AI Approach
Supervised stage
Their constitutional AI (CAI) consisted of two stages: a supervised stage and a reinforcement learning stage. In the supervised stage, they used a pretrained LM (“Helpful RLHF model” from their previous work) as a starting point, and red-teamed the model by presenting harmful prompts (by human workers) and sampled the responses. Then, (this is the most interesting part in my opinion!) they used natural language to ask the model to critique and revise its own response based on certain principles. Here’s an example from the paper:

Appendix C contains a list of principles (constitution) they used to create the critique-revision requests. The paper doesn’t talk much about how they came up with the principles but according to Anthropic’s website, the principles were based on existing documents such as Universal Declaration of Human Rights or Apple’s Terms of Service. As shown in the example above, a response can go through multiple critique-revision requests. The authors found that generally the more revisions mean less harmfulness although the first revision contributes most.
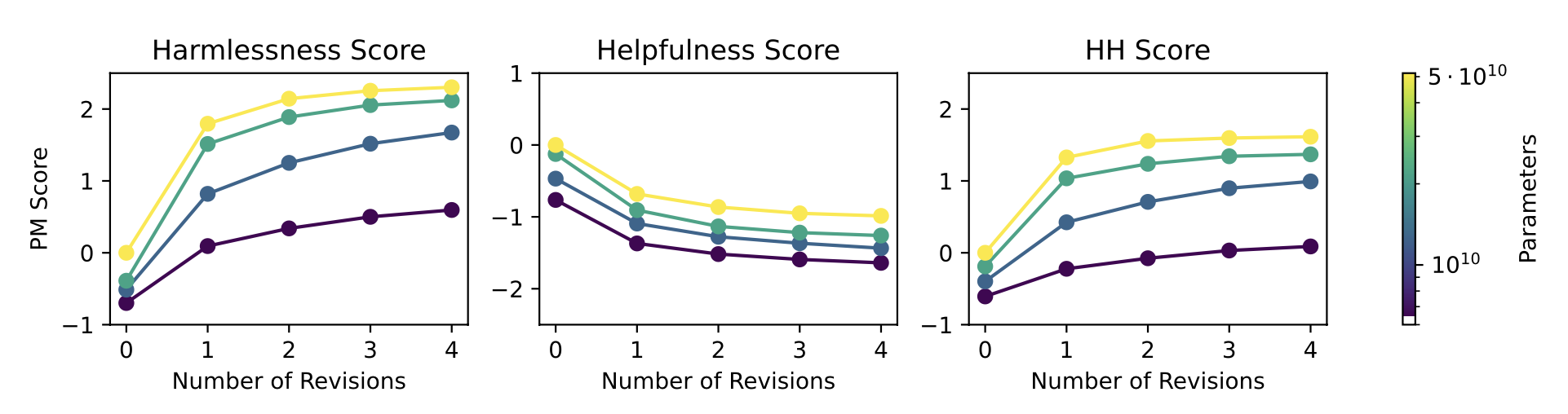
Reinforcement learning (RL) stage
The main idea behind this stage is identical to the RL stage in RLHF. The goal is to distill knowledge from a group of responses by training a reward model. The key difference is that these responses are now generated by a model not human (the supervised learning model from the previous stage). The authors called this reward model “feedback model” although it was a bit unclear which exact LMs they were referring to.
Another interesting aspect they added here was a “chain-of-thought” approach. This was inspired by Let’s Verify Step by Step, a paper we covered in a previous journal club meeting. Here, after getting a response, the authors added the natural-language phrase “Let’s think step by step” to generate richer intermediate responses from the model.

In their final model (Reinforcement Learning-Constitutional AI with Chain of Thought, or RL-CAI w/ CoT), the authors found a major improvement in harmlessness Elo score without compromising the helpfulness Elo score much. Note that in the figure below, Elo score of 0 on the y axis (starting point of the RL model) represents the supervised learning model (SL-CAI), which means the SL-CAI model was used as initial base model for RL.
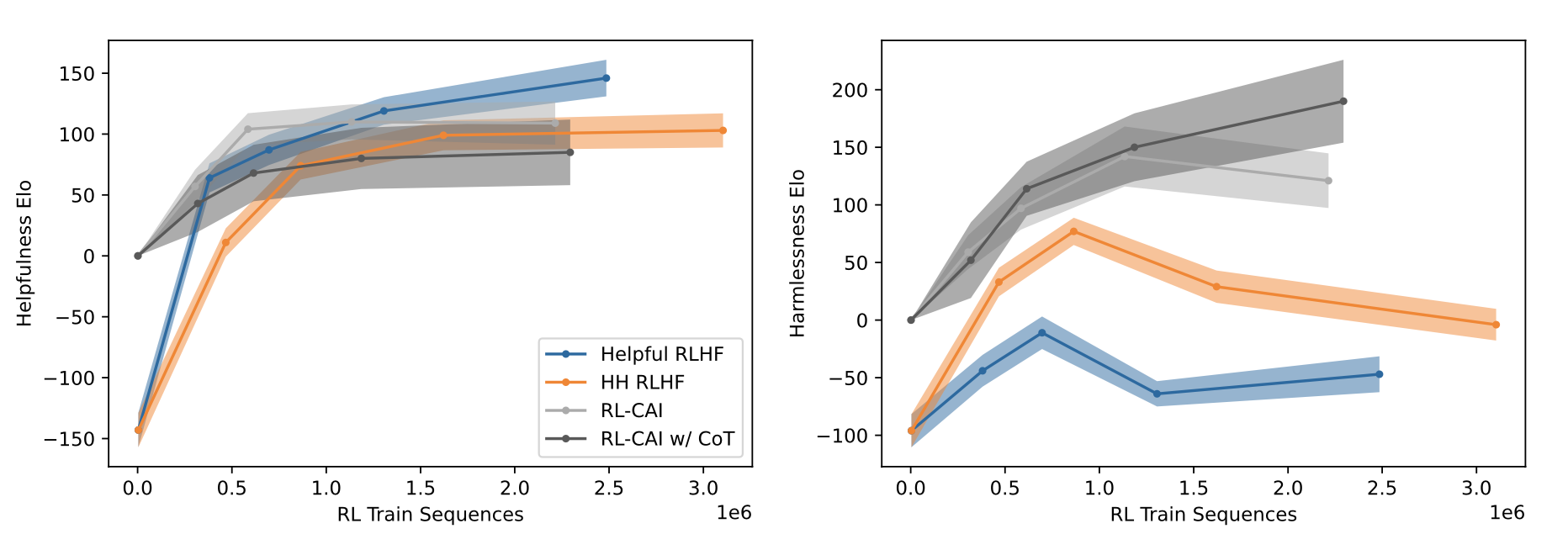
One interesting aspect of the RL model the authors shared was its behavior when the model was over-fitted. They found that in this case, the response often included boilerplate language such as “you are valid, valued, and cared for.”

“Broader Impacts”
At the end of the paper, the authors emphasized that natural language feedback could change AI behavior and potentially increase robustness because red-teaming efforts could become more scalable (because feedback supervision can be generated by a model not humans). In section 6.2 Broader Impacts, they briefly mentioned the potential harm of the constitutional AI approach. Using natural language to change AI behavior means it will become much easier to train a malicious AI assistant especially given that this method reduces the need for human feedback.
Group discussion
First of all, compared to other on-average deep learning papers, we found this paper easier to read. We also appreciated that the authors provided numerous examples. We could see they also tried to do a better job at providing many details of the model although still not enough, especially when they were referring to their previous work.
Harmlessness as an easy alignment
Some of us suspected that the authors might have chosen harmlessness as their main target of alignment perhaps because it was relatively easier to tackle than other alignment such as helpfulness. The authors did mention the tension between harmfulness and helpfulness in the paper in that an AI assistant could become harmful if it was too eager to be helpful (e.g., providing a detailed answer to a prompt about how to commit a crime). We talked about more nuanced alignments (such as humor) and whether it would be possible to use natural language to change model behavior. Some of us pointed out that harmlessness could be relatively easy because diametrically opposed examples could be easily found in languages.
Does chain-of-thought count as an explanation?
Many of us were skeptical of treating responses from the chain-of-thought approach as explanations. Most examples shown in the paper seemed reasonable but given that what the model did with a CoT request was nothing more than just generating more detailed responses, we agreed that we should not treat them as step-by-step deductive reasoning. We were interested in looking at CoT examples that might sound gibberish and redundant. I personally also thought this was one of the examples of ML practitioners anthropomorphizing a behavior of an ML model.
No more efforts to understand the model
Most of us were surprised that the approach of using natural language to critique and revise its own behavior seemed to have worked. Before I read the paper, I was very curious to know what constraints they came up with and how they tried to model complex social concepts such as justice and harm. The fact that their approach seemed to be working was interesting but this also meant that we are in an era where we are no longer trying to change the model behavior at a lower level, but rather we treat the language models as if they are something we don’t completely understand. This paper was completely missing explanations of why this approach actually worked. From my perspective, as other numerous deep learning papers, this paper was saying “we tried this, we don’t exactly know why it works, but it seems to work.”
Why diminish the work and labor of human annotators?
In the abstract and at the end of the paper, the authors kept saying their model was trained “without any human labels identifying harmful outputs.” All of us agreed that this was an exaggeration. To train the supervised model, they needed human annotators, and once the supervised model was ready, then they were able to generate AI feedback. Given that Anthropic is a for-profit company that sells AI assistant software, highlighting that the maintenance cost of their system is cheaper than others because human feedback can be replaced by AI feedback, could be a good marketing strategy, but at the cost of marginalizing human labor.
How did you come up with the principles?
In Appendix C, the authors provided a comprehensive list of all principles they used to generate critique-revision responses. These were the core principles that guided the model behavior but the authors didn’t mention much about how they curated the list. Some principles were general and others were more specific to particular types of harms such as racism and misogyny. We suspected that there had been an iterative curation process to narrow the list down to these 16 principles specifically. If these were the main drivers of changes in model behavior, we think they should have provided much more details.
The double-edged sword
Finally, some of us were disappointed that the authors didn’t elaborate much on the potential harm of their approach. They spent a lot of time talking about harmlessness of their algorithms and yet they really fell short when talking about social impacts of their model, especially regarding lowering the barrier for experimenting with LMs and automating supervision by removing human further out of the loop. Particularly for the former, we agreed that it wouldn’t be surprising to see, in near future bad actors take advantage of this approach and come up with a highly toxic, malicious, and harmful AI assistant.
If you found this post useful, you can cite it as:
@article{
austinmljc-2023-constitutional-ai,
author = {Hongsup Shin},
title = {Constitutional AI: Harmlessness from AI Feedback},
year = {2023},
month = {08},
day = {31},
howpublished = {rl{https://austinmljournalclub.github.io}},
journal = {Austin ML Journal Club},
url = {https://austinmljournalclub.github.io/posts/20230831/},
}