The Austin ML Journal Club brings together ML/AI practitioners for monthly deep dives into seminal research. We read papers in advance, meet virtually under Chatham House Rule, and critically examine methodologies, experimental design, and real-world applicability.
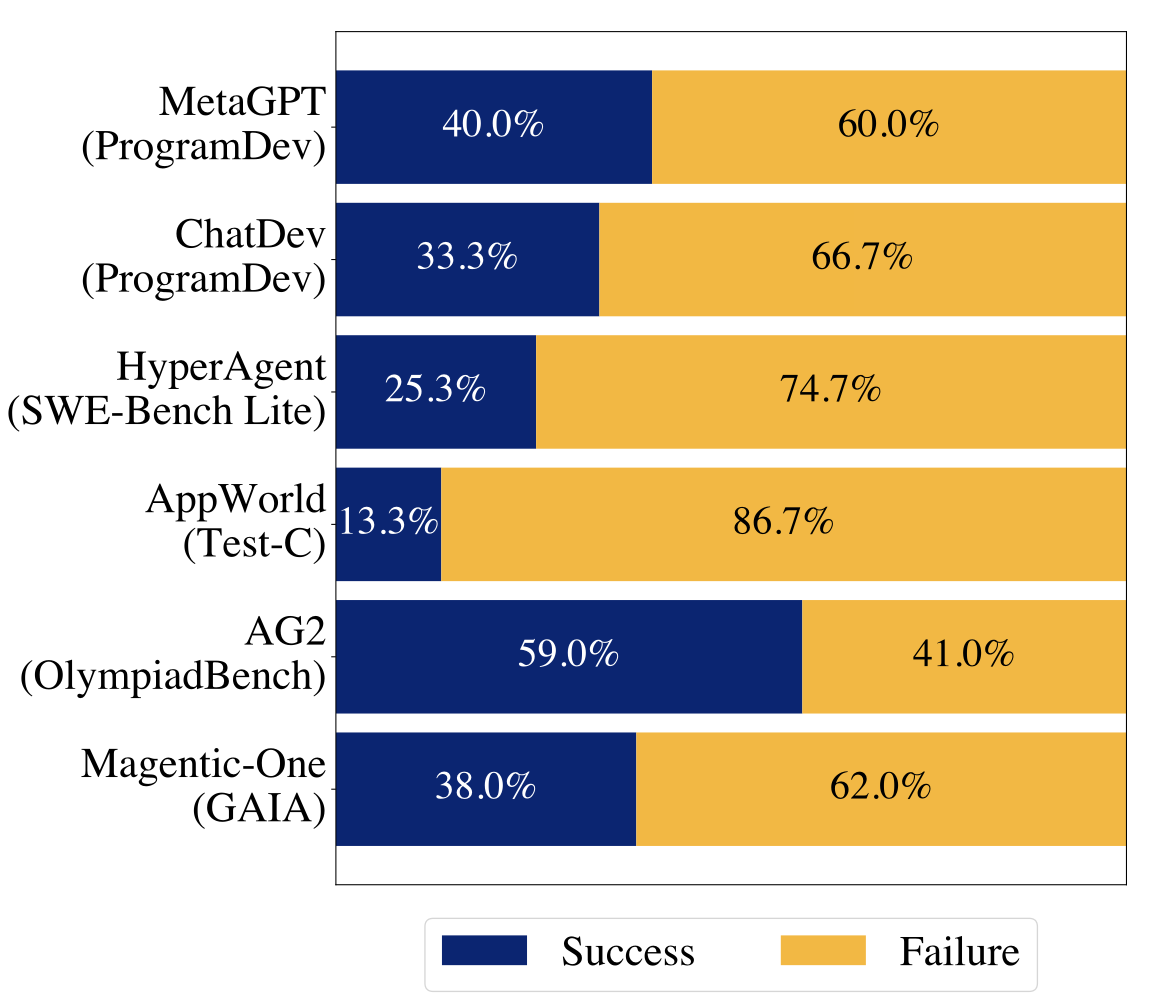
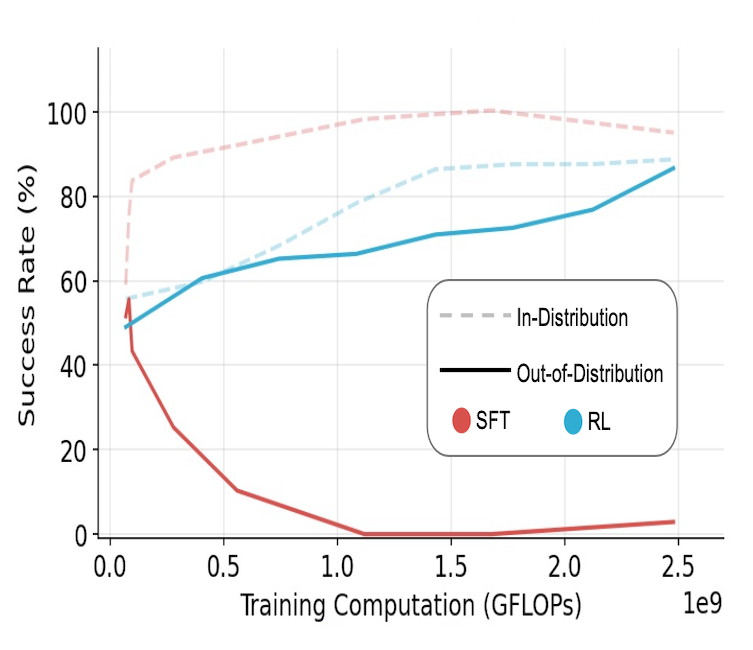
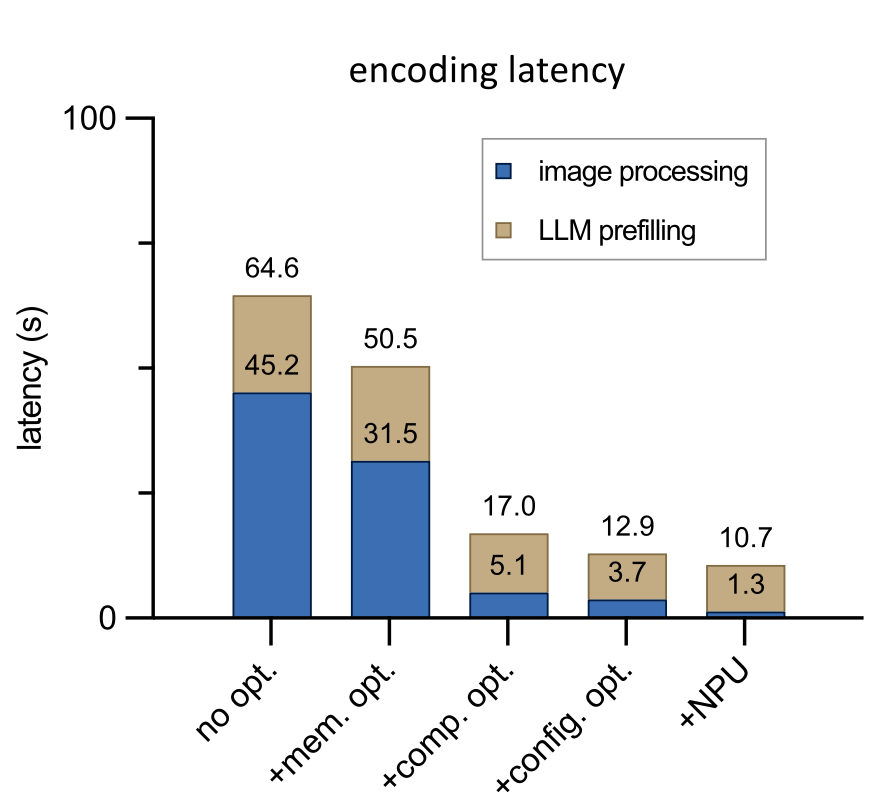
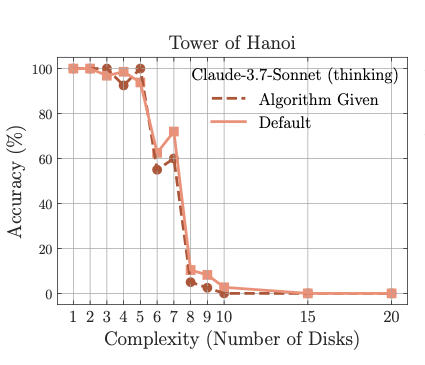

Modeling Tabular Data using Conditional GAN
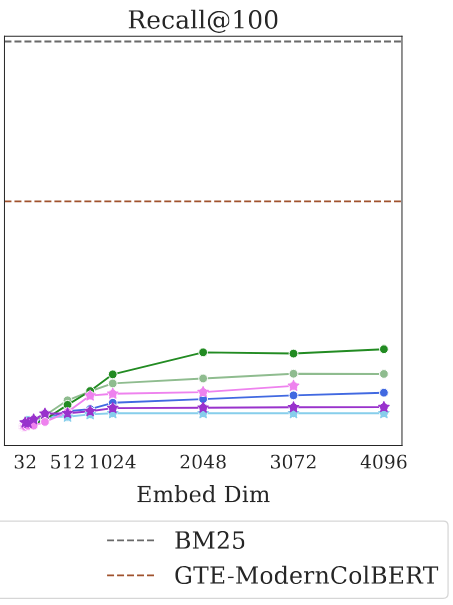
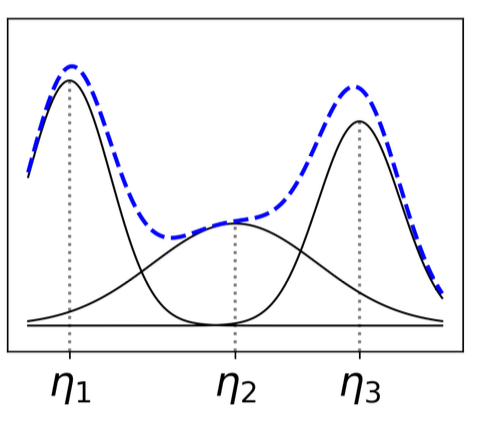
Tabular data synthesis (data augmentation) is an under-studied area compared to unstructured data. This paper uses GAN to model unique properties of tabular data such as mixed data types and class imbalance. This technique has many potentials for model improvement and privacy. The technique is currently available under the Synthetic Data Vault library in Python.




No matching items